
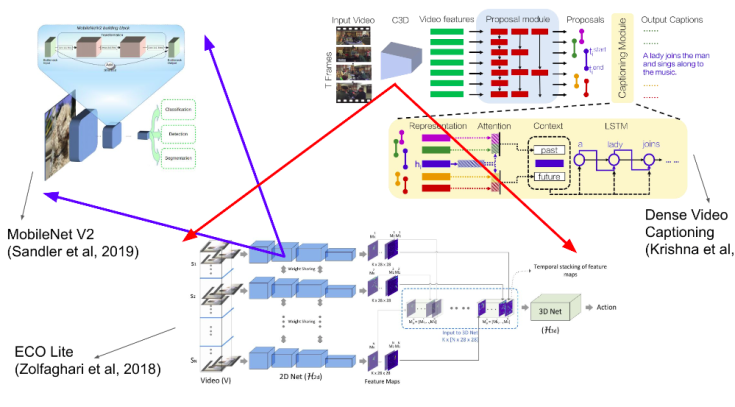
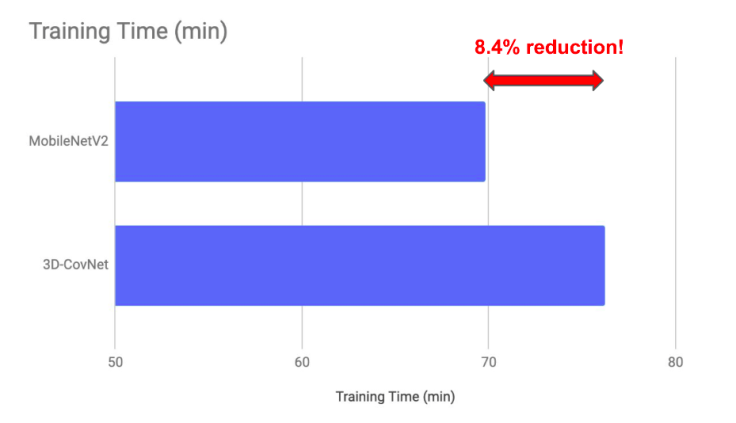
We modified the ideas for Bidirectional Attentive Fusion for Dense Video Captioning using 2D convolutions with MobilenetV2 and LSTMs, achieving 8.4% reduction in training time and very similar accuracy as state-of-the-art.
GitHub Link: https://github.com/asawaswapnil/DenseVideoCaptioning
